Generative Adversarial Network with Bells and Whistle
Dissecting GAN paper and it's implementation
Overview
This section will explain the general idea about GAN (Generative Adverserial Network)
We will approximate $\mathbb{P}_{data}$ with a parametric function $G(z,\theta_g)$ which is a function of random variable $Z \sim \mathbb{P}_z$ and has distribution $\mathbb{P}_{g}$. The authors of GAN call $G(z,\theta_g)$ as generator and the function is in the form of artificial neural network. There are many ways to make generator generates sample as close as possible to samples that are generated by $\mathbb{P}_{data}$ for instance we can set a loss function between our generator's samples and real data then minimize the loss function with somekind of optimization algortihm, this is kind of method is a direct approach to the problem, instead of using direct approach GAN framework is inspired by min-max game from game theory, by introducing a new function called discriminator $D(x)$ with distribution $\mathbb{P}_{\text{is real}}$. Discriminator inputs are samples from $\mathbb{P}_{data}$ and $\mathbb{P}_{g}$ and return the probability of input was generated by $\mathbb{P}_{data}$, so the perfect discrimiator will return 1.0 if the input comes from real data and return 0.0 if input comes from generator, we can also consider discriminator as an "ordinary binary classifier" which classify wheter a data is real or fake. On the other hand generator tries to generate samples to look as close as possible to real data in order to outsmart the discriminator or in other word it try to make discriminator to classify an input as real whenever the input is fake (generated by generator). More formally discriminator and generator aims are as follow:
Discriminator Task:
- Maximize the value of $\mathbb{P}_\text{is real}(x_1,x_2,\dots,x_n)$ where $x_1,x_2,\dots,x_n$ are samples from real dataset
- Minimize the value of $\mathbb{P}_\text{is real}(G(z_1),G(z_2),\dots,G(z_n))$ where $G(z_1),G(z_2),\dots,G(z_n)$ are samples generated by generator
Generator Task:
- Maximize the value of $\mathbb{P}_\text{is real}(G(z_1),G(z_2),\dots,G(z_n))$
From the list above we can see that generator and discriminator competing to each other, this raise some important questions, for instance how come this form of competing model achieve our main goal a.k.a make a model that can generate samples that look like real data. When we suppose to stop the training ?. To answer those questions we will start by defining how our criterion should look like.
Setting up the Criterion
Let's begin with the first task of discriminator, Suppose that $x_1,x_2,\dots,x_n$ is our real samples we wish to maximize $\mathbb{P}_\text{is real}(x_1,x_2,\dots,x_n)=\prod_{1}^{n}\mathbb{P}_\text{is real}(x_i)=\prod_{1}^{n} D(x_i)$, but from computation point of view choosing this value as criterion is a bad decision since it saturate small probability value to zero, here is a code snippet that illustrate the phenomena
From the output of the code above, we can see that small values equal to zero after multipication, which is obviously not the exact value, this is caused by the decimal rounding computer does, and since we multiply many smalls values that are rounded down the result become extremely small as the result it close to zero then computer round it to zero, as an alternative since logarithm function is strictly increasing function hence $\log\left[\prod_{1}^{n} D(x_i)\right]=\sum_{1}^{n} \log D(x_i)$ will serve the same purpose, since it is only the scaled version of $\prod_{1}^{n} D(x_i)$. In statistics it is usually called log-likelihood, and since the dataset can be considered as generated by empirical distribution, we can express the log-likelihood in term of expectation,
$$\begin{aligned}\sum_{1}^{n} \log D(x_i)&=n\sum_{1}^{n}\frac{1}{n} \log D(x_i) \\ &= n\sum_{1}^{n} \mathbb{P}_{data}(x_i) \log D(x_i) \\ &=n\mathbb{E}_{x\sim \mathbb{P}_{data}}\left[log(D(x))\right] \end{aligned}$$With the same line of reasoning for the second task of discriminator we want to maximize the value of $n\mathbb{E}_{z\sim \mathbb{P}_g}\left[1-log(D(G(z)))\right]$, note here we turn minimizing task into maximizing task, so to do both task we with to maximize
$$\begin{aligned}V^{\prime}(D,G)=n\mathbb{E}_{x\sim \mathbb{P}_{data}}\left[log(D(x))\right]+n\mathbb{E}_{z\sim \mathbb{P}_z}\left[\log(1-D(G(z)))\right]\end{aligned}$$Since $n$ is only a scaler we can drop $n$ such that we want to maximize
$$\begin{aligned}V(D,G)=\mathbb{E}_{x\sim \mathbb{P}_{data}}\left[log(D(x))\right]+\mathbb{E}_{z\sim \mathbb{P}_z}\left[\log(1-D(G(z)))\right]\end{aligned}$$Now move to the goal of generator, if we denote optimal discriminator as $D^* = \text{argmax}_D V(G,D)$ then the goal of generator is to minimize
$$\begin{aligned}V(D^{*},G)=\mathbb{E}_{x\sim \mathbb{P}_{data}}\left[\text{log}(D^{*}(x))\right]+\mathbb{E}_{z\sim \mathbb{P}_z}\left[\log(1-D^{*}(G(z)))\right]\end{aligned}$$Optimal Discriminator
In this section we aim to find $D^{*}(x)= \text{argmax}_{D}V(D,G)$. By the Law of Unconcious Statistician
hence
$$\begin{aligned} V(D,G)&=\mathbb{E}_{x\sim \mathbb{P}_{data}}\left[\log D(x)\right]+\mathbb{E}_{z\sim \mathbb{P}_z}\left[\log (1-D(G(z)))\right] \\ &=\mathbb{E}_{x\sim \mathbb{P}_{data}}\left[\log D(x)\right]+\mathbb{E}_{x\sim \mathbb{P}_g}\left[\log (1- D(x))\right] \\ &= \int_{x}\log D(x)\mathbb{P}_{data}(x)dx+\int_{x}\log (1-D(x))\mathbb{P}_g(x)dx \\ &=\int_{x}\log D(x)\mathbb{P}_{data}(x) + \log (1-D(x))\mathbb{P}_g(x)dx \end{aligned}$$Now we want to find the value of that maximize the integran by using elementary calculus,i.e setup the derivation to zero, as follow:
$$\Longleftrightarrow \frac{d\log D(x)\mathbb{P}_{data}(x) + \log (1-D(x))\mathbb{P}_g(x)}{d D(x)}=\frac{\mathbb{P}_{data}(x)}{D(x)}-\frac{\mathbb{P}_g(x)}{1-D(x)}=0 \\ \Longleftrightarrow \mathbb{P}_{data}(x)=D(x)\mathbb{P}_g(x)+D(x)\mathbb{P}_{data}(x) \\ \Longleftrightarrow D(x)=\frac{\mathbb{P}_{data}(x)}{\mathbb{P}_g(x)+\mathbb{P}_{data}(x)}$$So we get the optimal value for discriminator i.e $D^{*}(x)=\frac{\mathbb{P}_{data}(x)}{\mathbb{P}_g(x)+\mathbb{P}_{data}(x)}$
Optimal Generator
Now we have an optimal discriminator, next we want to find $G^* = \text{argmax}_G V(G,D^{*})$ but let's first expand $V(G,D^{*})$ :
$$\begin{aligned}V(G,D^{*})&=\int_{x}\log\left[\frac{\mathbb{P}_{data}(x)}{\mathbb{P}_g(x)+\mathbb{P}_{data}(x)}\right]\mathbb{P}_{data}(x)+\log\left[1-\frac{\mathbb{P}_{data}(x)}{\mathbb{P}_g(x)+\mathbb{P}_{data}(x)}\right]\mathbb{P}_g(x) dx \\ &=\int_{x}\log\left[\frac{2\mathbb{P}_{data}(x)}{2(\mathbb{P}_g(x)+\mathbb{P}_{data}(x))}\right]\mathbb{P}_{data}(x)dx+\int_{x}\log\left[\frac{2\mathbb{P}_g(x)}{2(\mathbb{P}_g(x)+\mathbb{P}_{data}(x))}\right]\mathbb{P}_g(x)dx \\ &= -\log 2 + \int_{x}\log\left[\frac{2\mathbb{P}_{data}(x)}{(\mathbb{P}_g(x)+\mathbb{P}_{data}(x))}\right]\mathbb{P}_{data}(x)dx-\log 2 + \int_{x}\log\left[\frac{2\mathbb{P}_g(x)}{(\mathbb{P}_g(x)+\mathbb{P}_{data}(x))}\right]\mathbb{P}_g(x)dx \\ &= -\log 4+2\mathbf{D}_{\text{Jensen-Shanon}}(P_g||P_{data})\end{aligned}$$So here we have nice interpretation because it is easy to find the minimium now, the minimum value of Jensen-Shanon divergence is atained when $\mathbb{P}_{data}(x)=\mathbb{P}_g(x)$ which cause $D^{*}(x)=\frac{\mathbb{P}_{data}(x)}{\mathbb{P}_g(x)+\mathbb{P}_{data}(x)}=\frac{1}{2}$ in other words when the min-max game equilibrium between generator and discriminator achieved, discriminator always return 0.5 for both fake and real data, which mean the discriminator is confused and cannot tell the difference between real and fake data. So theoritically the best time to stop the training is when discriminator return 50% confidence for both samples that generated by generator or real data, but this is only half of the story, we cannot guarantee that our neural network model or our optimization algortihm can achieve that condition.
Training GAN
Training GAN is somekind of art as it is not as straight forward as training "conventional" neural network
architecture. The original paper of GAN itself does not provide detail about training procedure but more
like general framework and the detail is left to us. Since
GAN is very popular many researchers and engineers working on it, there is some nice article out there the
provide technique to train GAN effectively
such as ganhack ganhack
Training Discriminator
Remember that our discriminator goal is to maximize $\mathbb{E}_{x\sim \mathbb{P}_{data}}\left[\log(D(x))\right]+\mathbb{E}_{z\sim \mathbb{P}_z}\left[\log(1-D(G(z)))\right]$ notice that we can turn is maximizing problem into minimizing binary cross entropy loss and the sthocastic version (sum over batch) will look like this $L_{\text{BCE}}=-\sum^{n}_{i=1}y_i\log{\hat{y}_i}+(1-y_i)\log(1-\hat{y}_i)$ according to ganhack tips it is better to split the batch between real batch and fake batch. Feed forward the fake-only batch compute the loss, feed forward the real-only batch compute the loss, sum up both loss from real-only and fake-only batch then compute the gradient, finally update weight. As for illustration below is diagram of discrimiator forward and backward propagation. The blue line is the flow of forward propagation from real data to summing operator, and the yellow is from fake data, the red line is the flow of gradients from summed loss to discriminator.
Training Generator
Training generator is straight forward since we will only feed noise. The quirk is only we will not minimize $\mathbb{E}_{z\sim \mathbb{P}_z}\left[\log(1-D(G(z)))\right]$ rather than maximize $\mathbb{E}_{x\sim \mathbb{P}_{data}}\left[\log(D(G(z)))\right]$ hence we should assign 1.0 as label (true label) for generator output during training the generator
GAN inference
The inference is very straigh forward, just ignore the discrimiator part, generate noise and feed it to generator
Implementation
The code implementation is in python I have tried to make the code as
readable as possible by minimizing the boilerplates,
we will use pytorch framework to help with the automatic differentiation part for backpropagation which is
not essential in this article, also the neural network model for
discrimiator and generator are mlp with super simple architecture, and the BCE loss is written explicitly to
enhance understanding, but
in practice I really recommend to use
Import needed library, and use manual seed so we will get the same result if we run it several times
We will use MNIST dataset, for ease of use let use the one provided by pytorch
Now define our simple generator and discrimiator architecture
Define our hyperparameter
Define loss function and optimizer, here in practice it is possible that discrimiator return zero and log at zero
is undefined, to fix this we will add very small number
Write function for viewing the generated results
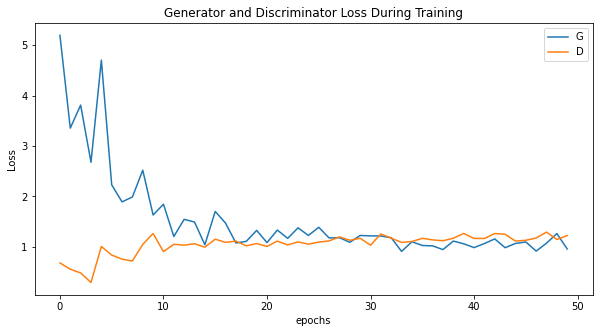
Train our GAN and wait for some minutes
View the result, if you run the code correctly after the training is finished then we can see the loss plot and
some generated result by running the code snippet bellow